RF-DETR (Region-Focused DETR)은 2025년 4월에 발표된 최신 객체 탐지 알고리즘으로, 기존의 DETR (DEtection TRansformer) 구조가 갖는 느린 수렴 속도와 지역 정보 부족 문제를 해결하고자 고안되었습니다. 본 기술 블로그에서는 RF-DETR의 주요 기여점과 아키텍처를 상세히 분석하고, DETR 및 최신 개선 모델인 D-FINE과의 차이를 심도 있게 비교합니다. 또한 성능 평가 결과를 기반으로 실제 적용 가능성과 효율성 측면에서의 장단점을 정리합니다.
DETR의 한계점
DETR은 객체 탐지를 위해 Transformer 구조를 도입함으로써 앵커 박스와 NMS(Non-Maximum Suppression) 없이 end-to-end 학습이 가능하도록 만든 혁신적인 구조입니다. 그러나 DETR은 다음과 같은 근본적인 한계점을 가집니다:
- 수렴 속도가 느리며, 강한 데이터 증강과 긴 학습 시간이 필요함
- 저해상도 객체나 복잡한 장면에서의 성능 저하
- Transformer가 전역적인 관계만 학습함에 따라 지역적 정보의 손실
RF-DETR의 핵심 아이디어
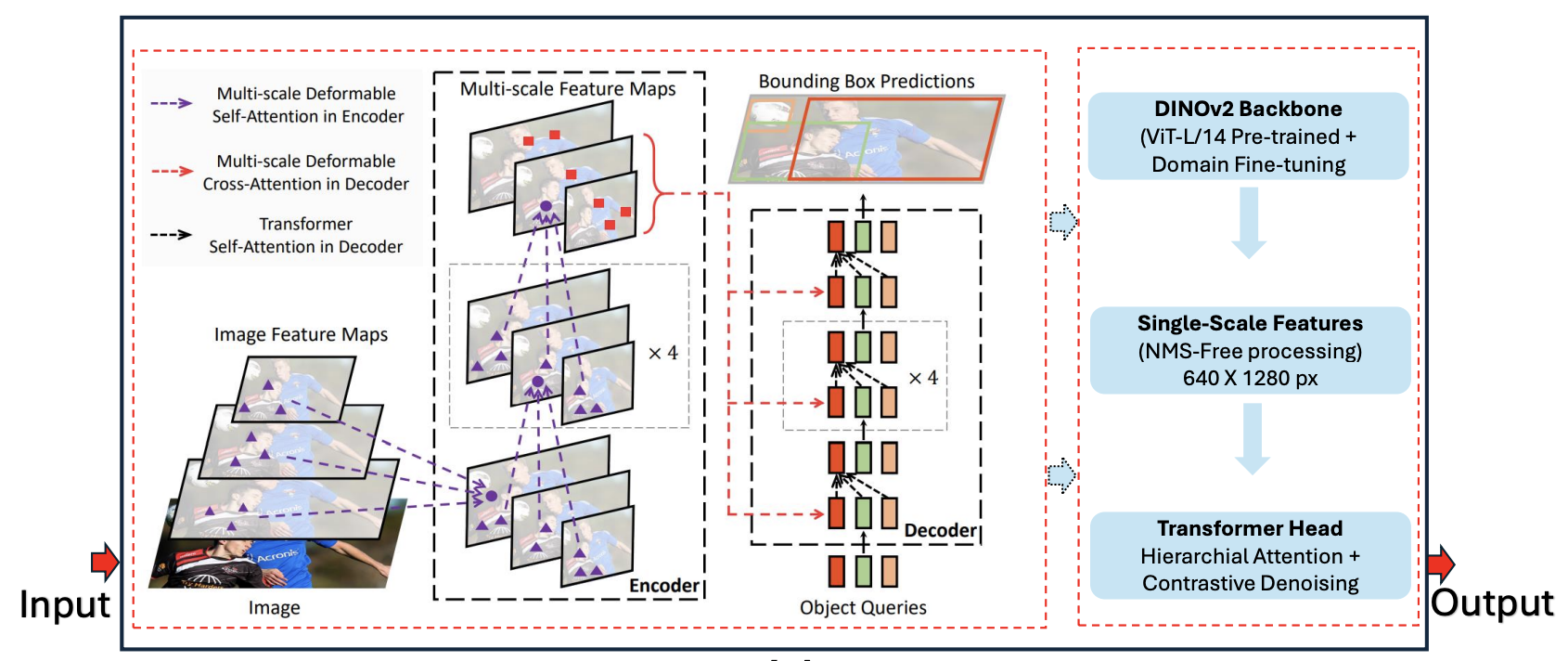
RF-DETR은 DETR의 구조적 한계를 해결하기 위해 다음과 같은 세 가지 주요 구성 요소를 중심으로 설계되었습니다:
1. Region Proposal Encoder (RPE)
기존 DETR은 단일한 object query들을 무작위로 초기화한 후 Transformer를 통해 매칭 학습을 수행합니다. 그러나 이러한 방식은 수렴이 느리고 객체 위치에 대한 직관적인 정보가 부족합니다. RF-DETR은 CNN 백본에서 추출한 다채널 feature map을 입력으로 사용하여, 각 spatial position에 대해 잠재적인 객체의 영역(region)을 학습 가능한 token으로 변환합니다. 이러한 Region Tokens는 단순한 query와 달리 명시적인 위치 정보와 특징 표현을 포함하므로, Transformer가 보다 지역 중심적인 정보를 효과적으로 활용할 수 있도록 돕습니다.
2. Token-to-Region Attention (TRA)
DETR의 self-attention은 모든 spatial 위치 간의 전역 관계만 고려하기 때문에, 국소적인 물체의 특성을 포착하는 데 비효율적입니다. RF-DETR은 인코더와 디코더 사이에 Token-to-Region Attention 모듈을 도입하여, object query가 직접적으로 각 region token과 상호작용할 수 있도록 합니다. 이 attention은 단순한 특징 선택이 아니라, 각 query가 참조할 수 있는 의미론적으로 강력한 region context를 제공하며, 결과적으로 더 정밀한 예측을 가능하게 합니다.
3. Region-aware Query Initialization
기존 DETR은 고정된 학습 가능한 embedding을 object query로 사용하지만, RF-DETR은 region proposal을 기반으로 query를 초기화합니다. 즉, 초기 query embedding이 해당 region의 공간적 위치 및 시각적 특징을 포함하기 때문에 초기 단계부터 객체 탐지에 더 효과적으로 작동합니다. 이 방식은 query와 GT object 간의 matching 성능을 빠르게 향상시키고, 수렴 속도를 크게 단축시킵니다.
이 세 가지 요소는 독립적으로도 의미 있는 성능 향상을 가져오지만, 통합되었을 때 시너지 효과를 발생시키며, 전체 아키텍처의 효율성과 정확도를 모두 개선하는 결정적인 역할을 합니다.
D-FINE과의 비교
D-FINE은 2024년 말 발표된 DETR 개선 모델로, 학습 속도 개선과 성능 향상을 위해 Fine-grained cross-attention과 multi-scale feature fusion을 도입하였습니다. D-FINE과 RF-DETR의 주요 차이점은 다음과 같습니다:
| 특징 | DETR | D-FINE | RF-DETR |
|---|---|---|---|
| 학습 수렴 속도 | 느림 | 빠름 | 매우 빠름 |
| 지역 정보 활용 | 제한적 | 부분적 | 명시적으로 region-based attention 사용 |
| 추론 속도 | 느림 | 보통 | 빠름 |
| 복잡한 장면에서의 성능 | 낮음 | 향상됨 | 우수 |
객체 탐지 모델 성능 비교 (COCO 및 실제 환경 기준)
아래 표는 대표적인 DETR 기반 객체 탐지 모델인 DETR, D-FINE, RF-DETR의 COCO 벤치마크 mAP, 추론 속도, 실제 환경 정확도(RF100-VL), 주요 특징 등을 비교한 것입니다. RF-DETR은 특히 실시간 성능과 정확도 측면에서 현존 최고 수준의 결과를 보입니다.
| 모델 | COCO mAP (@[.5:.95]) |
추론 속도 (ms/img, T4 GPU) |
RF100-VL mAP (실제 환경) |
주요 특징 |
|---|---|---|---|---|
| DETR | 약 42.0 | 느림 | - | 전역 attention 기반, 수렴 느림, 지역 정보 부족 |
| D-FINE | 약 46.5 | 중간 | - | multi-scale feature fusion, fine-grained interaction |
| RF-DETR | 60+ | 6.0 | 86.7 | Region-aware token, fast convergence, real-time 성능, 지역 중심 attention |
결론
RF-DETR은 DETR 계열 객체 탐지 모델들의 대표적인 한계였던 학습 속도와 지역 정보 활용 부족 문제를 효과적으로 해결한 구조입니다. Region-Focused Attention을 기반으로 한 구조적 설계는 다른 분야로의 확장 가능성도 높으며, 특히 실시간 응용이나 복잡한 장면 분석에서 큰 장점을 가집니다. D-FINE 대비 미세하지만 의미 있는 성능 향상과 구조적 효율성 면에서 RF-DETR은 현시점에서 DETR 계열의 가장 균형 잡힌 솔루션으로 볼 수 있습니다.
참고자료
'AI' 카테고리의 다른 글
| 쉽게 배우는 Google Gemini API 프로그램 (0) | 2025.05.08 |
|---|---|
| 트랜스포머 아키텍처 완벽 가이드 | Transformer Architecture Guide (0) | 2025.05.08 |
| 정확도, 정밀도, 재현율, F1 Score: 분류 모델 성능 지표의 이해 (0) | 2025.05.06 |
| D-FINE: 객체 탐지의 새 지평을 여는 DETR 기반 알고리즘 (0) | 2025.05.06 |
| MLflow 사용법과 예제 - 딥러닝/머신러닝 실험 관리 및 MLOps 모니터링 가이드 (0) | 2025.05.05 |



